
IPv6 路由协议
一、ISIS协议:
A、概述:
为了支持IPv6路由的处理计算,ISIS新增了两个TLV和一个新的NLPID
**IPv6 Reachability TLV:**该TLV Type为236(0xEC),在该TLV字段中,定义了路由信息的前缀、度量值等信息来说明当前网络的可达性。
• 236号TLV字段解释:
▫ Type:8 bit,TLV类型,此时值为236(0xEC)。
▫ Length:8 bit,TLV的Value部分长度。
▫ Metric:32 bit,度量值。
▫ U:1 bit,Up/Down位,标识这个前缀是否是从高Level通告下来的。
▫ X:1 bit,External Original位,标识这个前缀是否是从其他路由协议中引入的。
▫ S:1 bit,Sub-TLV Present位,子TLV标识位(可选)。
▫ R:5 bit,Reserve位,保留位。
▫ Prefix Length:8 bit,前缀长度。
▫ Prefix:IPv6地址前缀。
▫ Sub-TLV Length:8 bit,子TLV长度。若S位置1,则存在。
▫ Sub-TLV:子TLV。若S位置1,则存在。
**IPv6 Interface Address TLV:**该TLV Type为232(0xE8),相当于IPv4中的132号TLV(IP Interface Address TLV),只是将原来的32比特的IPv4地址修改为128比特的IPv6地址。IPv6 Interface Address TLV结构如下所示:
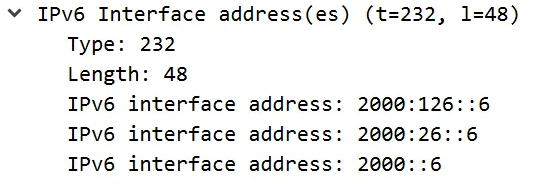
232号TLV字段解释:
▫ Type:8 bit,TLV类型,此时值为232(0xE8)。
▫ Length:8 bit,TLV的Value部分长度。
▫ Interface Address:128 bit,IPv6地址。
NLPID:表示网络层协议报文的一个8比特的字段值,IPv6的NLPID值是142,如果ISIS支持IPv6,那么向外发布IPv6的路由信息时就必须携带NLPID值。该字段通过TLV 129来携带。
B、多拓扑的MT ID:
ISIS多拓扑MT ID,增加了四种新的TLV:222、229、235、237。
ISIS MT是指在一个ISIS自治域内运行多个独立的IP拓扑。例如IPv4拓扑和IPv6拓扑,而不是将它们视为一个集成的单一拓扑。
这有利于ISIS在路由计算中根据实际组网情况来单独考虑IPv4和IPv6网络。根据链路所支持的IP协议类型,不同拓扑运行各自的SPF计算,实现网络的互相屏蔽。
如图,数值表示对应链路上的开销值,Router A、Router C和Router D支持IPv4和IPv6双栈,Router B只支持IPv4协议,不支持IPv6协议。

如果Router A不支持ISIS MT,进行SPF计算时只考虑单一的整体拓扑,则Router A到Router C的最短路径是Router A–Router B–Router C,但是由于Router B不支持IPv6,所以Router A发送的IPv6报文将无法通过Router B到达Router C。
如果在Router A上使能了ISIS MT,此时Router A在进行SPF计算时会根据不同的拓普进行计算,当Router A需要发送IPv6报文给Router C时,Router A只考虑IPv6链路来确定IPv6报文转发路径,则Router A–Router D–Router C路径被选为从Router A到Router C的IPv6最短路径。IPv6报文被正确转发。
二、BGP4+ 协议:
A、概述:
传统的BGP只能管理IPv4单播的路由信息,对于使用其他的网络层协议的应用,在跨AS传递的时候就会受到一定的限制,因此就需要BGP的多协议扩展MP-BGP,MP-BGP就是为了提供对多种网络层协议的支持,对BGP-4进行的一个扩展,目前MP-BGP使用扩展属性和地址簇来实现对IPv6、组播和VPN相关内容的支持,BGP协议原有的报文机制和路由机制并没有改变。
MP-BGP对IPv6单播网络的支持特性称为BGP4+,对IPv4的组播网络的支持特性称为MBGP,MP-BGP为IPv6单播路由和IPv4组播网络分别建立独立的拓扑结构,并且将其路由信息存储在独立的路由表中,保持单播IPv4网络、单播IPv6网络和组播网络之间路由信息的相互隔离,也就实现了用单独的路由策略来维护好各自网络的路由。
BGP在IPv4网络中支持自动聚合和手动聚合两种方式,而IPv6网络中仅支持手动聚合方式
B、MP-BGP拓展属性:
在BGP使用的报文中,与IPv4相关的三处信息都由Update报文携带,这三处信息分别是NLRI字段、Next-Hop属性、Aggregator属性。为实现对多种网络层协议的支持,BGP需要将网络层协议的信息反映到NLRI以及Next-Hop,因此MP-BGP引入了两个新的可选非过渡路径的属性。
**MP-REACH-NLRI:**多协议可达NLRI,用于发布可达路由以及下一跳信息,如左图
**MP-UNREACH-NLRI:**多协议不可达NLRI,用于撤销不可达路由信息,如右图
**MP-BGP采用地址簇(Address Family):**来区分不同的网络层协议,OPEN报文中的Optional Parameters字段是一个可选参数值,用于BGP验证或多协议扩展等功能的协商,并且携带相应的地址簇参数


C、和 IPv4 BGP 对比:
三、IPv6过渡技术
A、概述:
IPv6 在 1992 年被提出,到现在已经二十多年,IPv6 技术的发展已经很成熟,那么 IPv4 能否一下全部切换到 IPv6 呢,答案肯定是否定的。主要因为 IPv6 不是 IPv4 的改进,IPv6 是一个全新的协议,在链路层是不同的网络协议,不能直接进行通信。而且目前几乎都是在使用 IPv4,所以这种转换可能会持续很久。
所以IPv4到v6的过渡必须是一个循序渐进的过程,在体验IPv6带来的好处的同时仍能与网络中其余的IPv4用户通信。能否顺利地实现从IPv4到IPv6的过渡也是IPv6能否取得成功的一个重要因素。当前使用的过度技术有如下所示:

B、双栈技术:
IPv4 和 IPv6 有功能相近的网络层协议,都是基于相同的硬件平台,同一个主机同时运行 IPv4 和 IPv6 两套协议栈,具有 IPv4/IPv6 双协议栈的结点称为双栈节点,这些结点既可以收发 IPv4 报文,也可以收发 IPv6 报文。它们可以使用 IPv4 与 IPv4 结点互通,也可以直接使用 IPv6 与 IPv6 结点互通。双栈节点同时包含 IPv4 和 IPv6 的网络层,但传输层协议(如 TCP 和 UDP)的使用仍然是单一的。
优点:
处理效率高、无信息丢失
互通性好、网络规划简单
充分发挥 IPv6 协议的所有优点,更小的路由表、更高的安全性等。
资源占用多,运维复杂。
缺点:
无法实现 IPv4 和 IPv6 互通。且成本大,不能解决IPv4地址紧缺问题
对网络设备要求较高,内部网络改造牵扯比较大,周期性相比较较长。

双协议栈具有以下特点:
多种链路协议支持双协议栈:多种链路协议(如以太网)支持双协议栈。图中的链路层是以太网,在以太网帧上,如果协议ID字段的值为0x0800,表示网络层收到的是IPv4报文,如果为0x86DD,表示网络层是IPv6报文。
多种应用支持双协议栈:多种应用(如DNS/FTP/Telnet等)支持双协议栈。上层应用(如DNS)可以选用TCP或UDP作为传输层的协议,但优先选择IPv6协议栈,而不是IPv4协议栈作为网络层协议。
C、隧道技术:
1、概述:
隧道技术指将另外一个协议数据包的报头直接封装在原数据包报头前,从而可以实现在不同协议的网络上直接进行传输,这种机制用来在 IPv4 网络之上连接 IPv6 的站点,站点可以是一台主机,也可以是多个主机。隧道技术将 IPv6 的分组封装到 IPv4 的分组中,或者把 IPv4 的分组封装到 IPv6 的分组中,封装后的 IPv4 分组将通过 IPv4 的路由体系传输或者 IPv6 的分组进行传输。 隧道大体上分为两种隧道:IPv6 over IPv4隧道 与 IPv4 over IPv6隧道
优点:
无信息丢失
网络运维相比较简单
容易实现,只要在隧道的入口和出口进行修改
缺点:
隧道需要进行封装解封装,转发效率低。
无法实现 IPv4 和 IPv6 互通
无法解决 IPv4 短缺问题
NAT 兼容性不好
2、IPv6 over IPv4隧道分类:
原理介绍:

边界设备启动IPv4/IPv6双协议栈,并配置IPv6 over IPv4隧道。
边界设备在收到从IPv6网络侧发来的报文后,如果报文的目的地址不是自身且下一跳出接口为Tunnel接口,就要把收到的IPv6报文作为数据部分,加上IPv4报文头,封装成IPv4报文。
在IPv4网络中,封装后的报文被传递到对端的边界设备。
对端边界设备对报文解封装,去掉IPv4报文头,然后将解封装后的IPv6报文发送到IPv6网络中。
一个隧道需要有一个起点和一个终点,起点和终点确定了以后,隧道也就可以确定了。IPv6 over IPv4隧道的起点的IPv4地址必须为手工配置,而终点的确定有手工配置和自动获取两种方式。根据隧道终点的IPv4地址的获取方式不同可以将IPv6 over IPv4隧道分为手动隧道和自动隧道。
手动隧道:手动隧道即边界设备不能自动获得隧道终点的IPv4地址,需要手工配置隧道终点的IPv4地址,报文才能正确发送至隧道终点。
自动隧道:自动隧道即边界设备可以自动获得隧道终点的IPv4地址,所以不需要手工配置终点的IPv4地址,一般的做法是隧道的两个接口的IPv6地址采用内嵌IPv4地址的特殊IPv6地址形式,这样路由设备可以从IPv6报文中的目的IPv6地址中提取出IPv4地址。

**手动隧道:**根据IPv6报文封装的不同,手动隧道又可以分为IPv6 over IPv4手动隧道和IPv6 over IPv4 GRE隧道两种。
**IPv6 over IPv4手动隧道:**在隧道两端的边界路由设备上通过人工配置创建,需要静态指定隧道的源、目IPv4地址。隧道的端点设备必须支持IPv6/IPv4双协议栈。其它设备只需实现单协议栈即可。可以用于IPv6孤岛的通信。
**IPv6 over IPv4 GRE隧道:**在隧道两端的边界路由设备上通过人工配置创建,需要静态指定隧道的源、目IPv4地址。隧道的端点设备必须支持IPv6/IPv4双协议栈。其它设备只需实现单协议栈即可。可以用于IPv6孤岛的通信。与手动不同的是可以通过GRE头进行校验和关键字验证,提高了安全性。
**自动隧道:**根据IPv6报文封装的不同,自动隧道又可以分为IPv4兼容IPv6自动隧道、6to4隧道和ISATAP隧道三种。
**IPv6 over IPv4自动隧道:**只需要配置隧道的源地址,隧道的目的地址自动获取。隧道口的IPv6地址必须要使用一种特殊的IPv6地址(IPv4兼容IPv6地址–::IPv4地址/96)。其中::IPv4/96中的IPv4地址为隧道的源地址。
**6 to 4隧道:**只需要配置隧道的源地址,隧道的目的地址自动获取。隧道口的IPv6地址必须要使用一种特殊的IPv6地址(6to4地址—2002:IPV4地址::/48)
**6RD隧道:**与6to4隧道相比,6to4定义的地址前缀为2002::/16。而6RD的地址前缀是由运营商从自己的IPv6地址空间划分得到的,并且不仅限于16位。
6RD地址由6RD前缀(运营商划分出来的IPv6前缀)、IPv4地址(部分或全部IPv4地址)、子网ID与接口标识符四部分组成。
其中6RD前缀与IPv4地址统一起组成6RD委托前缀
其中IPv4的地址长度取决于配置的IPv4前缀长度,如果配置的是8,则从高位顺序删除8比特位,剩下的成为6RD委托前缀的一部分
IPv4前缀长度要根据两边的源IP地址来取(最大值为取两边IPv4地址由高到低的相同位数)例如:1.1.1.1与1.1.2.1 最大前缀长度可以为16。而1.1.1.1与1.2.1.1最大前缀长度可以为8
**ISATAP:**主要用于IPv4网络中的IPv4/IPv6主机访问IPv6网络的情况。ISATAP不仅是一种自动隧道技术,同时也可以进行地址自动配置。(隧道两端运行ND协议,为IPv4网络中的主机分配ISATAP地址,使其可以访问IPv6网络)。配置了ISATAP隧道后,IPv6网络会将底层的IPv4网络看作为一个非广播的点到多点的链路(NBMA)。
3、IPv4 over IPv6隧道技术分类:
在IPv4 Internet向IPv6 Internet过渡的后期,IPv6网络已被大量部署,此时可能出现IPv4孤岛。利用隧道技术可在IPv6网络上创建隧道,从而实现IPv4孤岛的互连。这类似于在IP网络上利用隧道技术部署VPN。在IPv6网络上用于连接IPv4孤岛的隧道,称为IPv4 over IPv6隧道。IPv4 over IPv6隧道技术原理如下图:

边界设备启动IPv4/IPv6双协议栈,并配置IPv4 over IPv6隧道。
边界设备在收到从IPv4网络侧发来的报文后,如果报文的目的地址不是自身,就要把收到的IPv4报文作为负载,加上IPv6报文头,封装到IPv6报文里。
在IPv6网络中,封装后的报文被传递到对端的边界设备。
对端边界设备对报文解封装,去掉IPv6报文头,然后将解封装后的IPv4报文发送到IPv4网络。
**IPv4 over IPv6手动隧道:**在隧道两端的边界路由设备上通过人工配置创建,需要静态指定隧道的源、目IPv6地址。隧道的端点设备必须支持IPv6/IPv4双协议栈。其它设备只需实现单协议栈即可。
**DS-Lite隧道:**待补充。
面试官:重点描述一下三大路由协议对IPv6的支持-腾讯云开发者社区-腾讯云



