
RRPP 协议
一、协议概述:
A、协议要素:
1、背景:
城域网和企业网大多采用环网来构建以提供高可靠性,但环上任意一个节点发生故障都会影响业务。环网采用的技术一般是RPR或以太网环。RPR需要专用硬件,因此成本较高。而以太网环技术日趋成熟且成本低廉,城域网和企业网采用以太网环的趋势越来越明显。
目前,解决二层网络环路问题的技术有 STP 和 RRPP 。STP应用比较成熟,但收敛时间在秒级。RRPP是专门应用于以太网环的链路层协议,具有比STP更快的收敛速度。并且RRPP的收敛时间与环网上节点数无关,可应用于网络直径较大的网络。
RRPP(快速环网保护协议)是一个专门应用于以太网环的链路层协议。它在以太网环完整时能够防止数据环路引起的广播风暴,而当以太网环上一条链路断开时能迅速恢复环网上各个节点之间的通信通路,具备较高的收敛速度。该协议属于H3C、华为私有协议。与STP协议相比,RRPP协议有如下优点:拓扑收敛速度快(低于50ms);收敛时间与环网上节点数无关
H3C所实现的RRPP协议还有如下特点:在相交环拓扑中,一个环拓扑的变化不会引起其他环的拓扑振荡,数据传输更为稳定; 支持RRPP环网的负载分担,充分利用了物理链路的带宽。
2、基本介绍:
RRPP域:具有相同的域ID和控制VLAN,并且相互连通的设备构成一个RRPP域。一个RRPP域具有RRPP主环、子环、控制VLAN、主节点、传输节点、主端口和副端口、公共端口和边缘端口等要素。如图所示,Domain 1就是一个RRPP域,它包含了两个RRPP环Ring 1和Ring 2,RRPP环上的所有节点属于这个RRPP域。
RRPP环:一个环形连接的以太网网络拓扑称为一个RRPP环。RRPP环分为主环和子环,环的角色可以通过指定RRPP环的级别来设定,主环的级别为0,子环的级别为1。一个RRPP域可以包含一个或多个RRPP环,但只能有一个主环,其它均为子环。如图 1所示,RRPP域Domain 1中包含了两个RRPP环Ring 1和Ring 2。Ring 1和Ring 2的级别分别配置为0和1,则Ring 1为主环,Ring 2为子环。
RRPP环的状态有以下两种:健康状态:整个环网物理链路是连通的;断裂状态:环网中某处物理链路断开。
控制VLAN:控制VLAN用来传递RRPP协议报文。设备上接入RRPP环的端口都属于控制VLAN,且只有接入RRPP环的端口可加入此VLAN。
每个RRPP域都有两个控制VLAN:主控制VLAN和子控制VLAN。主环的控制VLAN称为主控制VLAN,子环的控制VLAN称为子控制VLAN。配置时只需指定主控制VLAN,系统会自动把比主控制VLAN的VLAN ID值大1的VLAN作为子控制VLAN。
同一个RRPP域中所有子环的控制VLAN都相同,且主控制VLAN和子控制VLAN的接口上都不允许配置IP地址。
数据(保护)VLAN:与控制VLAN相对,数据VLAN用来传输数据报文。数据VLAN中既可包含RRPP端口,也可包含非RRPP端口。数据VLAN的转发状态由其所对应的RRPP域控制。同一环网上不同的RRPP域配置不同的保护VLAN,各RRPP域分别独立计算自己环上端口的转发状态。

3、节点和端口:
节点:RRPP环上的每台设备都称为一个节点。节点角色由用户的配置来决定,分为下列几种:
主节点:每个环上有且仅有一个主节点。主节点是环网状态主动检测机制的发起者,也是网络拓扑发生改变后执行操作的决策者。主节点处于Complete(Failed)状态时,RRPP环也处于Complete(Failed)状态。
Complete State(完整状态):当环网上所有的链路都处于UP状态,主节点可以从副端口收到自己发送的HELLO报文,就说主节点处于Complete状态,此时主节点会阻塞副端口以防止数据报文在环形拓扑上形成广播环路。
Failed State(故障状态):当环网上有链路处于故障状态时,主节点处于Failed状态,此时主节点的副端口放开对数据报文的阻塞,以保证环网上的通信不中断。
传输节点:主环上除主节点以外的其它所有节点,以及子环上除主节点、子环与主环相交节点以外的其它所有节点都为传输节点。传输节点负责监测自己的直连RRPP链路的状态,并把链路变化通知主节点,然后由主节点来决策如何处理。传输节点有如下3种状态:
Link-Up State(UP状态):传输节点的主端口和副端口都处于UP状态时,就说传输节点处于Link-Up状态。
Link-Down State(Down状态):传输节点的主端口或副端口处于Down状态时,就说传输节点处于Link-Down状态。
Pre-forwarding State(临时阻塞状态):传输节点的主端口或副端口处于阻塞状态时,就说传输节点处于Pre-forwarding状态。
边缘节点:同时位于主环和子环上的节点。是一种特殊的传输节点,它在主环上是传输节点,而在子环上则是边缘节点。边缘节点也有三种状态,和传输节点一样。
辅助边缘节点:同时位于主环和子环上的节点。也是一种特殊的传输节点,它在主环上是传输节点,而在子环上则是辅助边缘节点。辅助边缘节点与边缘节点成对使用,用于检测主环完整性和进行环路预防。
如上图所示,Ring 1为主环,Ring 2为子环。Device A为Ring 1的主节点,Device B、Device C和Device D为Ring 1的传输节点;Device E为Ring 2的主节点,Device B为Ring 2的边缘节点,Device C为Ring 2的辅助边缘节点。
主节点和传输节点各自有两个端口接入RRPP环,其中一个为主端口,另一个为副端口。端口的角色由用户的配置来决定。主节点的主端口和副端口在功能上有所区别:
主节点的主端口用来发送探测环路的报文,副端口用来接收该报文。
当RRPP环处于健康状态时,主节点的副端口在逻辑上阻塞数据VLAN,只允许控制VLAN的报文通过;
当RRPP环处于断裂状态时,主节点的副端口将解除数据VLAN的阻塞状态,转发数据VLAN的报文。
传输节点的主端口和副端口在功能上没有区别,都用于RRPP环上协议报文和数据报文的传输。
如图所示,Device A为Ring 1的主节点,Port 1和Port 2分别为其在Ring 1上的主端口与副端口;Device B、Device C和Device D为Ring 1的传输节点,它们各自的Port 1和Port 2分别为本节点在Ring 1上的主端口和副端口。

公共端口是边缘节点和辅助边缘节点上接入主环的端口,即边缘节点和辅助边缘节点分别在主环上配置的两个端口。边缘端口是边缘节点和辅助边缘节点上只接入子环的端口。
端口的角色由用户的配置决定。如图所示,Device B、Device C同时位于Ring 1和Ring 2上,Device B和Device C各自的端口Port 1和Port 2是接入主环的端口,因此是公共端口。Device B和Device C各自的Port 3只接入子环,因此是边缘端口。
4、RRPP环组:
RRPP环组是为减少Edge-Hello报文的收发数量,在边缘节点或辅助边缘节点上配置的一组子环的集合。这些子环的边缘节点都配置在同一台设备上,同样辅助边缘节点也都配置在同一台设备上。而且边缘节点或辅助边缘节点所在子环对应的主环链路相同,也就是说这些子环边缘节点的Edge-Hello报文都走相同的路径到达辅助边缘节点。
在边缘节点上配置的环组称为边缘节点环组,在辅助边缘节点上配置的环组称为辅助边缘节点环组。边缘节点环组内最多允许有一个子环发送Edge-Hello报文。
B、RRPP协议报文


协议报文各字段的含义如下:
Destination MAC Address:48bits,协议报文的目的MAC地址,范围是0x000FE2078217~0x000FE2078416。
Source Mac Address:48bits,协议报文的源MAC地址,总是0x000fe203fd75。
EtherType:8bits,报文封装类型域,总是0x8100,表示Tagged封装。
PRI:4bits,COS(Class of Service)优先级,总是0xe0。
VLAN ID:12bits,报文所在VLAN的ID。
Frame Length:16bits,以太网帧的长度,总是0x48。
DSAP/SSAP:16bits,目的服务访问点/源服务访问点,总是0xaaaa。
CONTROL:8bits,总是0x03。
OUI:24bits,总是0x00e02b。
RRPP Length:16bits,RRPP协议数据单元长度,总是0x40。
RRPP_VER:16bits,RRPP版本信息,当前是0x0001。
RRPP Type:8bits,RRPP协议报文的类型。5表示HELLO报文;6表示COMPLETE-FLUSH-FDB报文;7表示COMMON-FLUSH-FDB报文;8表示LINK-DOWN报文;10表示EDGE-HELLO报文;11表示MAJOR-FAULT报文。
Domain ID:16bits,报文所属RRPP域的ID。
Ring ID:16bits,报文所属RRPP环的ID。
SYSTEM_MAC_ADDR:48bits,发送报文节点的桥MAC。
HELLO_TIMER:16bits,发送报文节点使用的Hello定时器的超时时间,单位为秒。
FAIL_TIMER:16bits,发送报文节点使用的Fail定时器的超时时间,单位为秒。
LEVEL:8bits,报文所属RRPP环的级别。
二、工作原理:
A、定时器:
RRPP在检测以太网环的链路状况时,主节点根据Hello定时器从主端口发送Hello报文,根据Fail定时器判断副端口是否收到Hello报文。
Hello定时器:规定了主节点从主端口发送Hello报文的周期。 在同一RRPP域中,传输节点会通过收到的Hello报文来学习主节点上Hello定时器和Fail定时器的值,以保证环网上各节点定时器的值是一致的。
Fail定时器:规定了主节点从主端口发出Hello报文到副端口收到该报文的最大时延。在该定时器超时前,若主节点在副端口上收到了自己从主端口发出的Hello报文,主节点认为环网处于健康状态;否则,主节点认为环网处于断裂状态。
Fast-Hello定时器:规定了主节点从主端口发送Fast-Hello报文的周期。
Fast-Fail定时器:规定了主节点从主端口发出Fast-Hello报文到副端口收到该报文的最大时延。在该定时器超时前,若主节点在副端口上收到了自己从主端口发出的Fast-Hello报文,主节点认为环网处于健康状态;否则,主节点认为环网处于断裂状态。在同一RRPP域中,传输节点不会通过收到的Fast-Hello报文来学习主节点上Fast-Hello定时器和Fast-Fail定时器的值。
B、单域单环工作原理:
1、监测机制:
主节点通过轮询机制来主动检测环网状态并进行相应处理:
主节点周期性的从其主端口发送HELLO报文,依次经过各传输节点在环上传播。
如果环网上所有链路都处于UP状态,则主节点能够从副端口收到自己发送的HELLO报文,说明环网状态完整。
为了防止环上的数据报文形成广播环路,主节点阻塞其副端口。
环网完整时的情况如图所示

环网故障可以通过两种方式检测出来:
轮询机制:主节点通过轮询机制来主动检测环网状态:主节点周期性的从其主端口发送HELLO报文,依次经过各传输节点在环上传播。如果主节点在规定时间内收不到自己发送的HELLO报文,认为环网发生链路故障。主节点将状态切换到Failed状态,放开副端口,并从主、副端口发送COMMON-FLUSH-FDB报文通知环上所有传输节点刷新MAC表项和ARP/ND表项。
Link Down通知机制:节点总是在监测自己的端口链路状态,一旦发现端口Down将立即采取措施:
当主节点主端口Down后,主节点直接感知链路故障,立即放开副端口,并从副端口发送COMMON-FLUSH-FDB报文通知环上所有传输节点刷新MAC表项和ARP/ND表项。
当传输节点上的RRPP端口发生链路DOWN时,该节点将从与故障端口配对的状态为UP的RRPP端口发送LINK-DOWN报文通知主节点(LINK-DOWN上报过程如图4所示)。主节点收到LINK-DOWN报文后,放开副端口,立即将状态切换到Failed状态。由于网络拓扑发生改变,为避免报文定向错误,主节点还需要刷新MAC表项和ARP/ND表项,并从主、副端口发送COMMON-FLUSH-FDB报文通知所有传输节点刷新MAC表项和ARP/ND表项(主节点状态向Failed状态迁移过程如图5所示)。

Link Down通知机制提供了比轮询机制更快的环网故障处理机制,但是,如果LINK-DOWN报文在传输过程中不幸丢失了怎么办?这时主节点的轮询机制就派上了用场。如果主节点在规定时间内(这一时间由Fail定时器定义)仍没有在副端口收到自己的HELLO报文,则认为环网发生故障,对故障的处理过程与传输节点主动上报完全相同。
2、环网故障恢复检测及处理机制:
传输节点端口恢复的瞬间,主节点还不能马上知道这一信息,因此其副端口还处于放开状态。这时如果传输节点立即迁移回Link-Up状态,势必造成数据报文在环网上形成瞬时环路,因此处于Link-Down状态的传输节点的主、副端口都恢复时,传输节点立即阻塞刚刚恢复的端口,迁移到Pre-forwarding状态。传输节点端口恢复时的处理过程如图6所示。此时整个环网并没有恢复,环网恢复的过程是由主节点主动发起的。
环上所有链路恢复正常后,当处于Failed状态的主节点重新收到自己发出的HELLO报文,将阻塞副端口,将状态迁移回Complete状态。由于RRPP环拓扑已经改变,主节点要刷新MAC表项和ARP/ND表项,并从主端口发送COMPLETE-FLUSH-FDB通知所有传输节点刷新MAC表项和ARP/ND表项。处于Pre-forwarding状态的传输节点收到主节点发送的COMPLETE-FLUSH-FDB报文时,迁移到Link-Up状态,这样整个环网就恢复完成了。环网恢复的处理过程如图7所示。

如果COMPLETE-FLUSH-FDB报文在传播过程中丢失,还有一种备份机制来实现传输节点临时阻塞端口的恢复。传输节点处于Pre-forwarding状态时,如果在规定时间内(这一时间由Fail定时器定义)收不到主节点发来的COMPLETE-FLUSH-FDB报文,自行放开临时阻塞端口,并刷新本节点MAC表项和ARP/ND表项,恢复数据通信。
C、单域相交环工作原理:
1、组网结构:
另外,主环节点收到子环的COMMON-FLUSH-FDB或者COMPLETE-FLUSH-FDB报文时,都需要刷新MAC表项和ARP/ND表项;子环的COMPLETE-FLUSH-FDB不会导致主环传输节点放开临时阻塞端口。
单域实现方式中,主环的实现原理与单环相同,子环主节点的检测机制亦与单环相同。不同之处在于多环引入了SRPT检查机制,在子环的2条SRPT全部中断,子环主节点副端口放开之前,先阻塞边缘节点的边缘端口,以此来防止子环间形成数据广播环路。

2、SRPT状态检测机制产生背景:
SRPT就是指子环协议报文在主环中的通道。RRPP协议理论上把主环看作是子环的一个逻辑节点,子环的协议报文通过主环透传,主环将子环的协议报文(除了EDGE-HELLO报文)当作数据报文进行转发。
每个子环有2条SRPT,在图11中分别为S3-S2和S3-S4-S1-S2。在主环完整时,其主节点副端口处于阻塞状态,只有S3-S2是通的。主环故障时,如果故障发生在S3-S4-S1-S2上,则S3-S2是通的;
如果故障发生在S3-S2上,则S3-S4-S1-S2是通的;因此,在任意时刻,子环的2条SRPT中,最多只有1条是通的,这样就避免了子环协议报文在主环中形成数据环路。
如果子环的2条SRPT全部中断时,子环主节点收不到自己发出的HELLO报文,于是Fail定时器超时,子环主节点放开副端口,这样子环可以获得最大的通信通路,且不会形成环路。
但对于图11所示的在实际应用中采用较多的双归属组网中,双归属的两个子环Ring 2和Ring 3借助边缘节点和辅助边缘节点相互连接,本身就形成了一个环路。当主环Ring 1上子环的2条SRPT全部中断后,所有子环的主节点副端口放开,子环之间势必形成数据环路(数据报文走向如箭头所示)。
为了消除这一缺陷,引入了SRPT状态检查机制。由边缘节点和辅助边缘节点配合完成SRPT的状态检查,当边缘节点检测到SRPT中断后,在两个子环主节点副端口全部放开之前,阻塞两子环边缘节点的边缘端口,避免子环间形成数据环路。主环SRPT故障后保护机制产生作用效果如图12所示。

2、检测机制工作过程:
边缘节点是检查活动的发起者和决策者,辅助边缘节点是通道状态的监听者,并负责在通道状态改变时及时通知边缘节点。整个机制的过程描述如下
1、检查SRPT状态:子环的边缘节点通过连入SRPT的两个端口周期性向主环内发送EDGE-HELLO报文,依次经过环上各节点发往辅助边缘节点,如图13所示。
如果辅助边缘节点在规定时间内能够收到EDGE-HELLO报文,表明至少有1条SRPT正常,子环报文可以正常通过。反之,辅助边缘节点如果收不到EDGE-HELLO报文,说明2条SRPT全部中断,子环报文无法通过。

2、SRPT中断,阻塞边缘节点的边缘端口
辅助边缘节点检测到2条SRPT全部中断后,立即从边缘端口通过子环链路向边缘节点发送MAJOR-FAULT报文。如果此时子环上无故障,边缘节点能够收到MAJOR-FAULT,立即阻塞自己的边缘端口,如图14所示;如果子环上存在故障,边缘节点的边缘端口不会被阻塞。
MAJOR-FAULT报文是周期性发送的,如果边缘节点收到,其边缘端口继续阻塞;如果在规定时间内收不到报文,边缘端口自行放开。

3、子环故障,状态迁移到Failed

4、SRPT恢复
主环故障恢复的同时,子环的SRPT得到恢复,辅助边缘节点不再报告MAJOR-FAULT报文。
如果子环本身没有故障,其主节点重新收到自己发出的HELLO报文,于是阻塞副端口,切换到Complete状态,如图16所示。
4、SRPT恢复:
主环故障恢复的同时,子环的SRPT得到恢复,辅助边缘节点不再报告MAJOR-FAULT报文。
如果子环本身没有故障,其主节点重新收到自己发出的HELLO报文,于是阻塞副端口,切换到Complete状态,如图16所示。

5、子环协议通道恢复示意图
子环恢复后,主节点会从主端口发送COMPLETE-FLUSH-FDB报文。边缘节点收到报文后,如果其边缘端口处于阻塞状态,立即放开边缘端口,全网通信恢复。如图17所示。
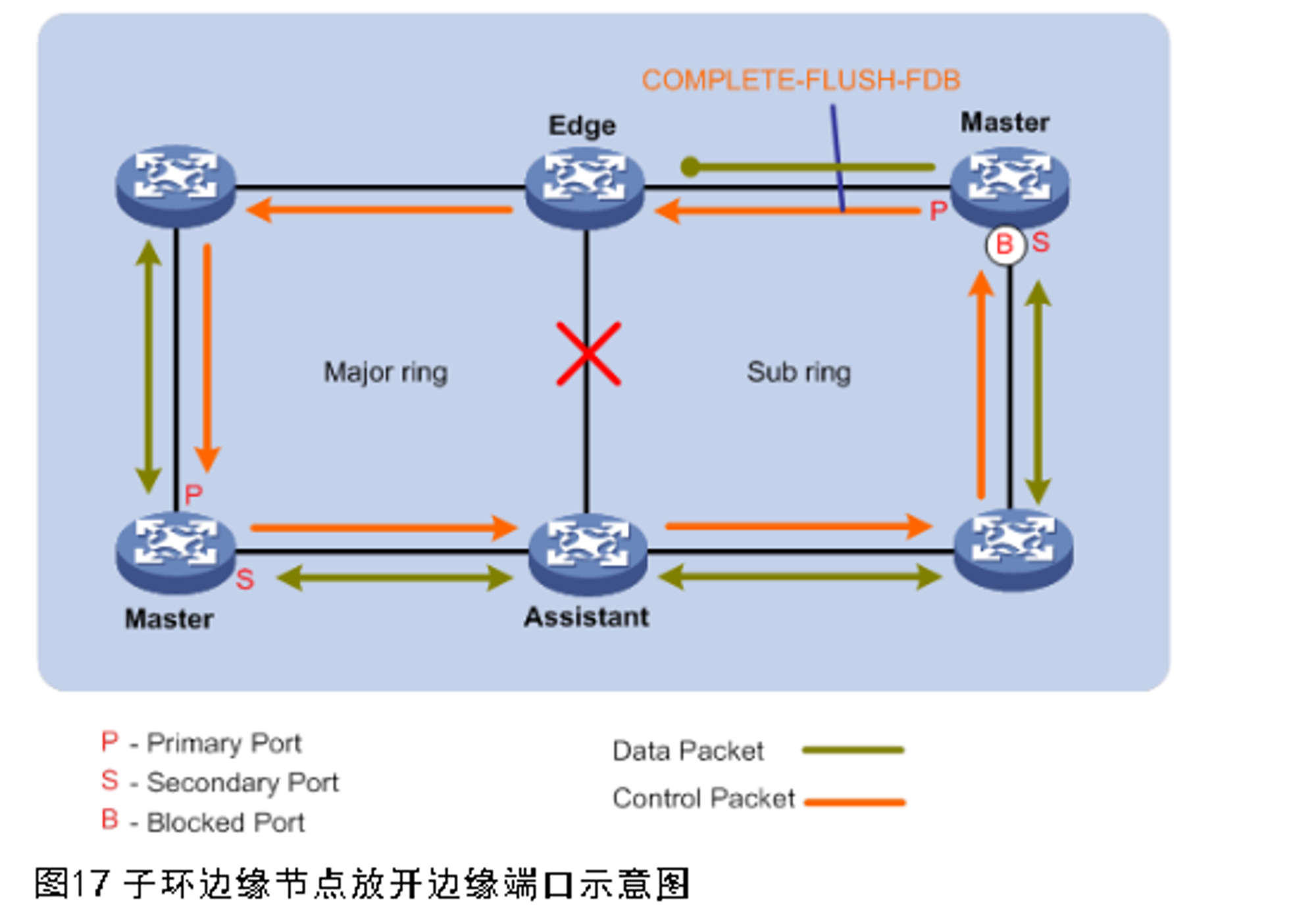
SRPT恢复时,如果此时子环存在故障,则子环无法恢复。此种情况下子环主节点不会发送COMPLETE-FLUSH-FDB报文,如果边缘节点的边缘端口处于阻塞状态,该端口只能在Fail定时器超时后自行放开



